∇
⇒
λ
拉格朗日乘数法
Lagrange Multipliers
约束优化公式
∇f(x,y) = λ∇g(x,y)
g(x,y) = c
1
建立拉格朗日函数 L(x,y,λ) = f(x,y) - λ(g(x,y) - c)
2
求解梯度方程组 ∇L = 0
3
验证解的性质(最大值/最小值)
↓
算法收敛路径
Convergence Visualization
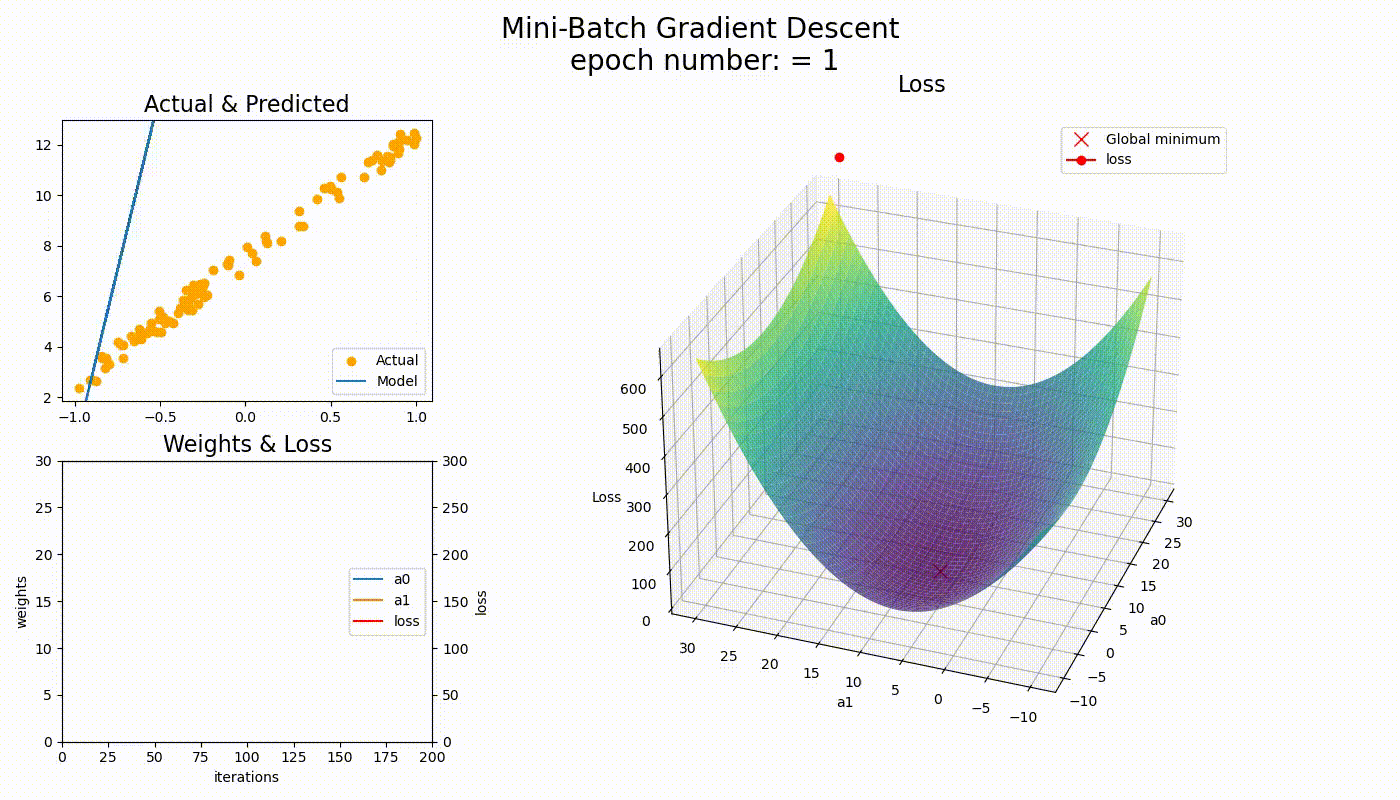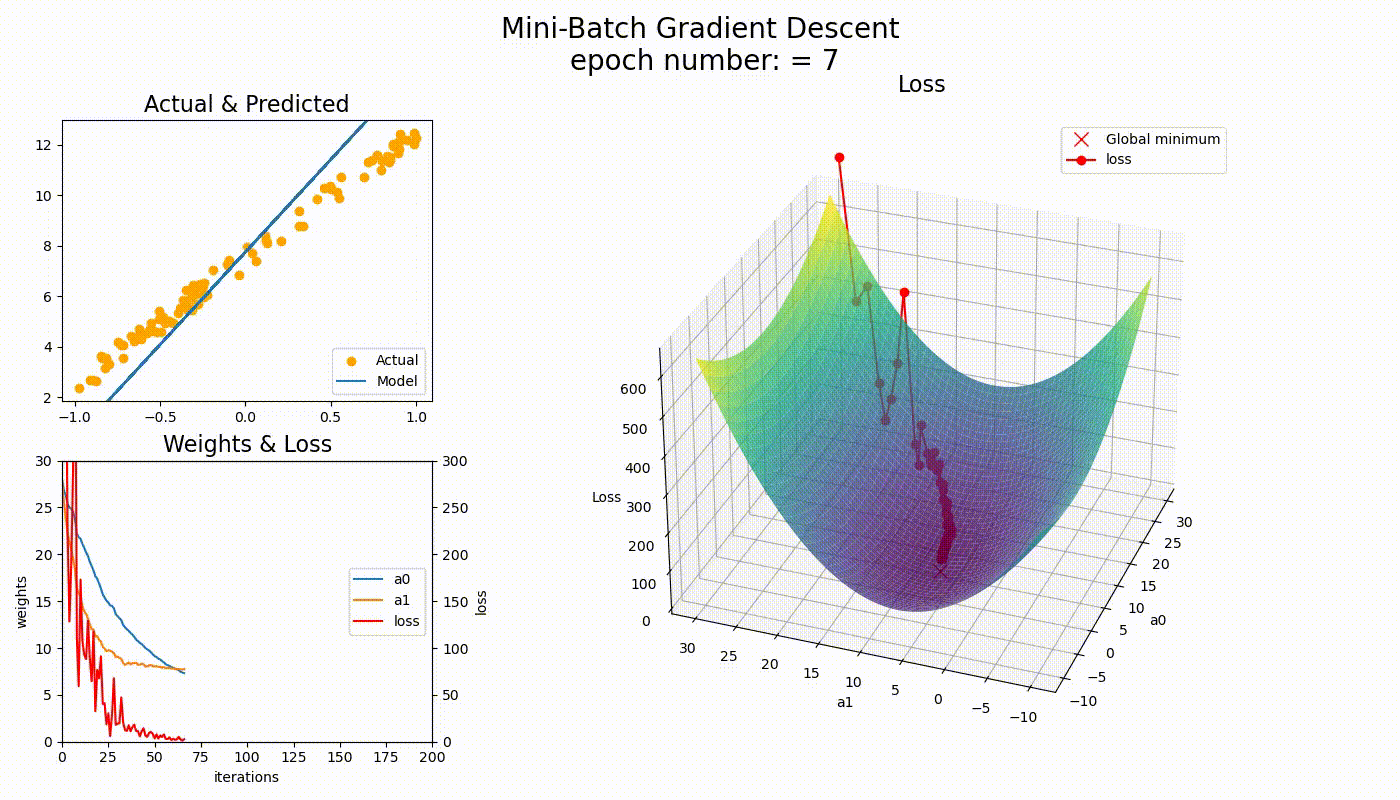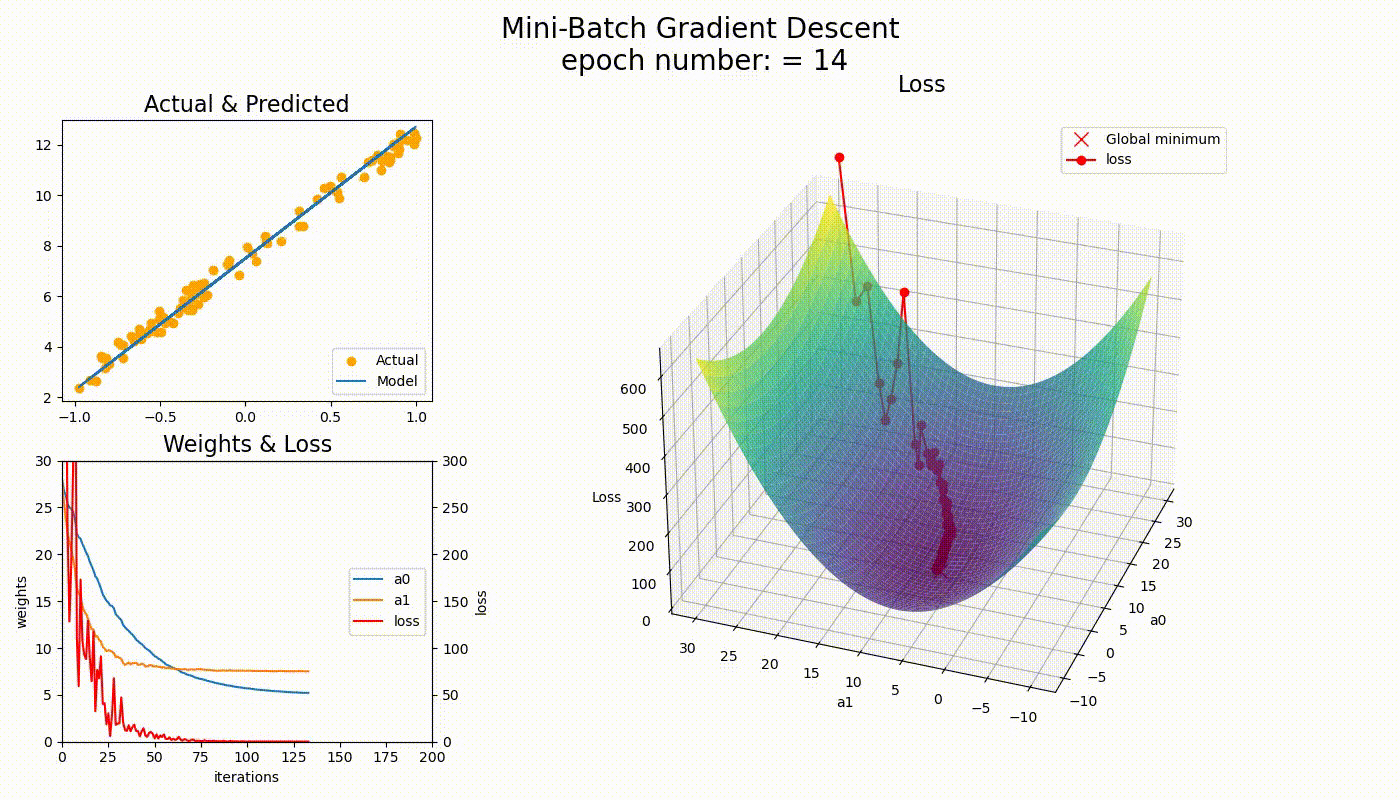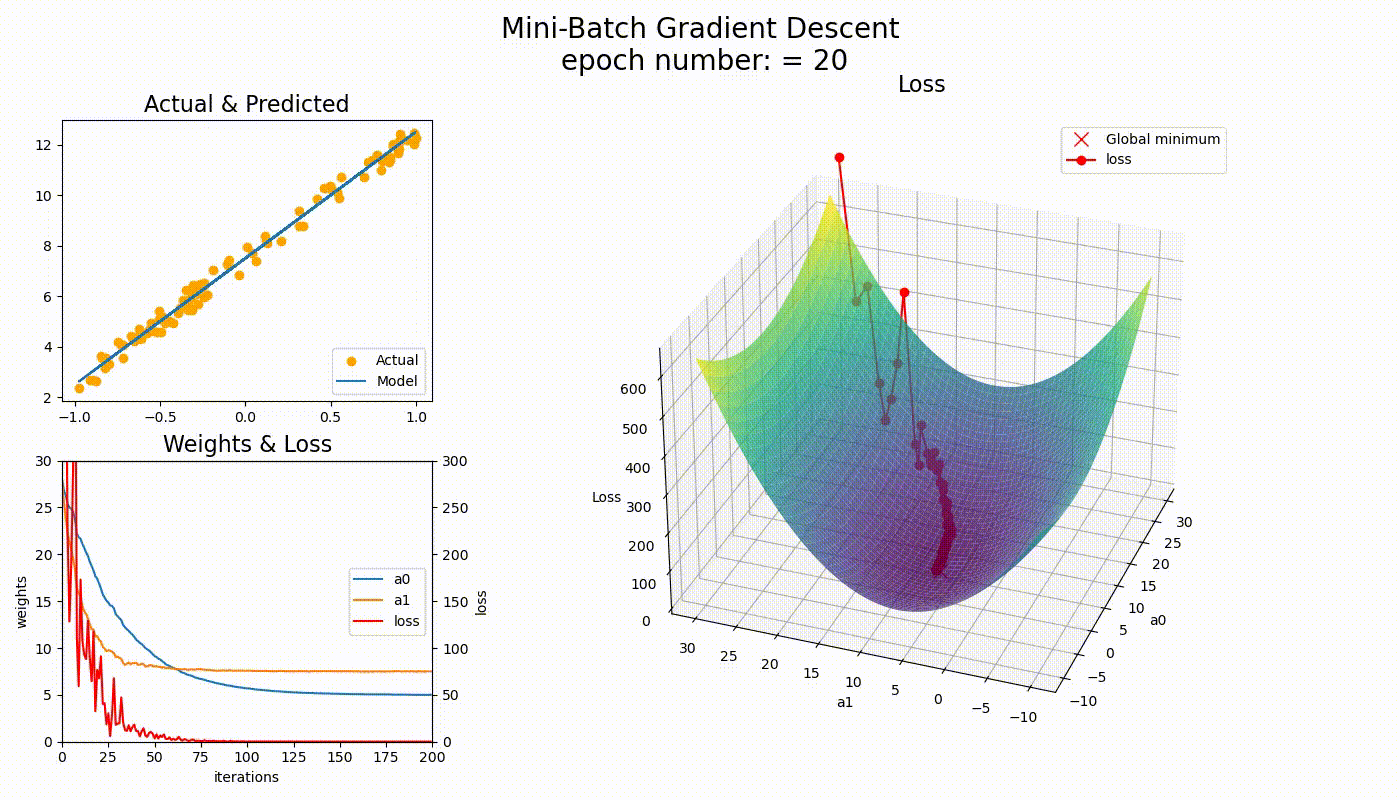
关键观察
- • BGD路径平滑,直接朝向最优解
- • SGD路径波动,但能逃离局部最优
- • MBGD介于两者之间,实用性最强
∞
2
🎯
核心要点总结
Key Takeaways
理论基础
- • 偏导数是梯度的基础
- • 链式法则处理复合函数
- • 拉格朗日法解约束优化
算法实践
- • BGD稳定,SGD快速
- • MBGD是实践首选
- • Adam适合大规模训练
视频资源
Video Learning

Gradient Descent in 3 minutes
Visually Explained
推荐观看Khan Academy和3Blue1Brown的微积分系列视频,直观理解概念。